01 — Overview
The problem with weekly reporting
Holey Moley Golf Club gets guest reviews across Google, Yelp, TripAdvisor, and Facebook — all funneled into ReviewTrackers. Every week, someone had to export a CSV, read through dozens of reviews, spot themes, calculate metrics against the company's custom fiscal calendar, and write a structured report for the management team's biweekly meeting.
The process took roughly 90 minutes, the output was inconsistent, and when things got busy it simply didn't get done. The feedback was there — we just weren't processing it fast enough to act on it.
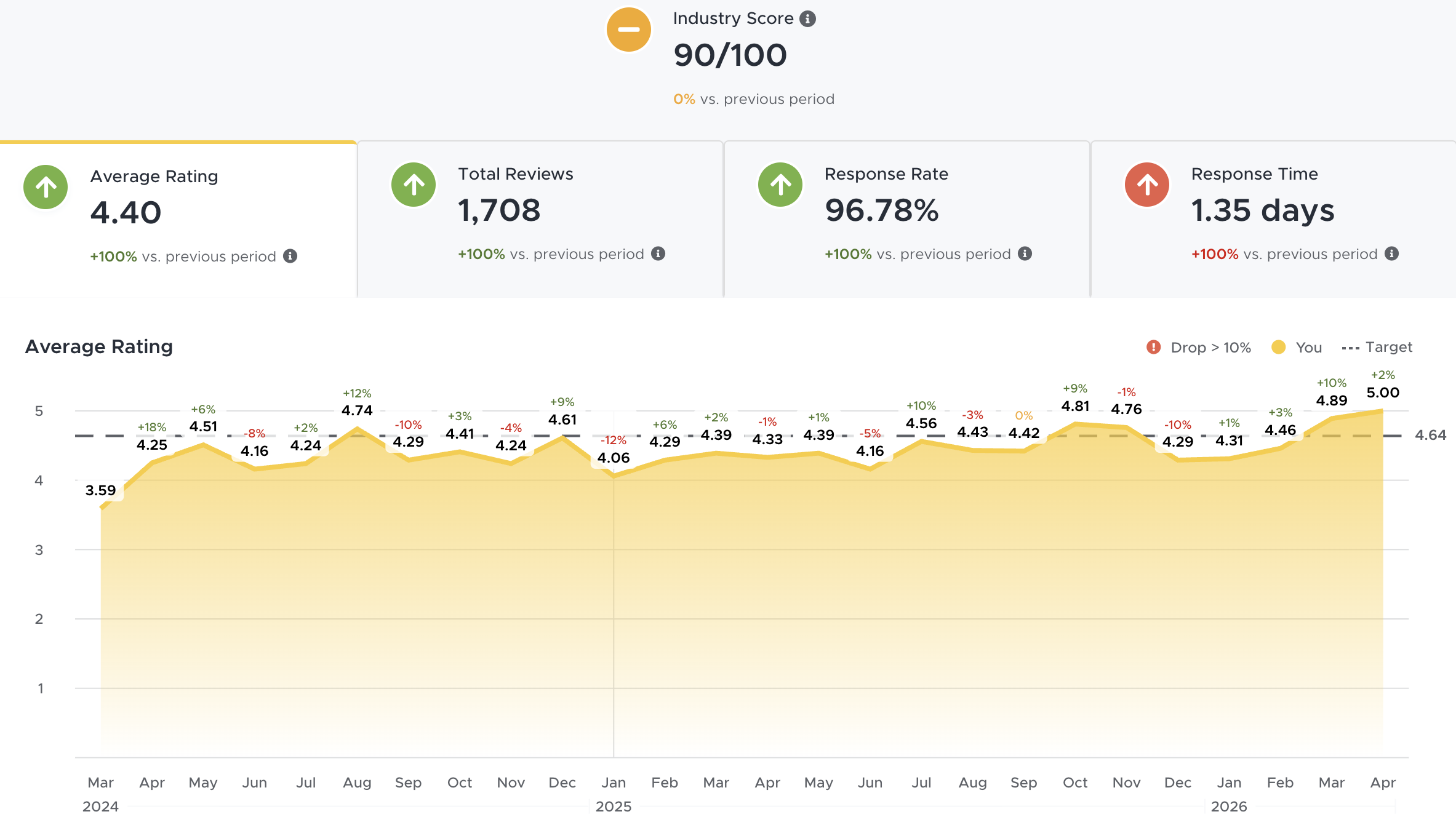
Dashboard view — reviews aggregated from Google, Yelp, TripAdvisor, Facebook
⚠ Before
Manual CSV exports, hand-written summaries, inconsistent delivery
Someone had to read every review, spot themes by gut feel, calculate period/YTD metrics manually, and format the report in Google Docs. Quality depended entirely on who did it and how much time they had that week.
✓ After
Drop a CSV, get a branded report with AI analysis in 60 seconds
A 20-node n8n pipeline handles everything — CSV ingestion, fiscal week calculation, Claude AI analysis with 76 weeks of historical memory, DOCX generation, Google Drive filing, and Telegram delivery.